Extract thalwegs
Background¶
Extracting channel networks from grid digital elevation models (DEMs) follows these precedures: (1) fill depressions/sinks in the original DEM; (2) calcuate flow direction and flow accumulation based on eight-direciton method (D8); (3) determine the flow accumulation threshold to derive a digital stream network.
Flow accumulation threshold is a parameter that identifies grids with flow accumulation greater than the threshold as a stream network. It varies with DEM resolution, raster size and geomorphic complexity. The optimal threshold is a trial and error based on user's goal. The smaller threhold will generate denser network. Below are river network extracted with three different threshold: 1e5, 1e6, and 1e7, respectively:
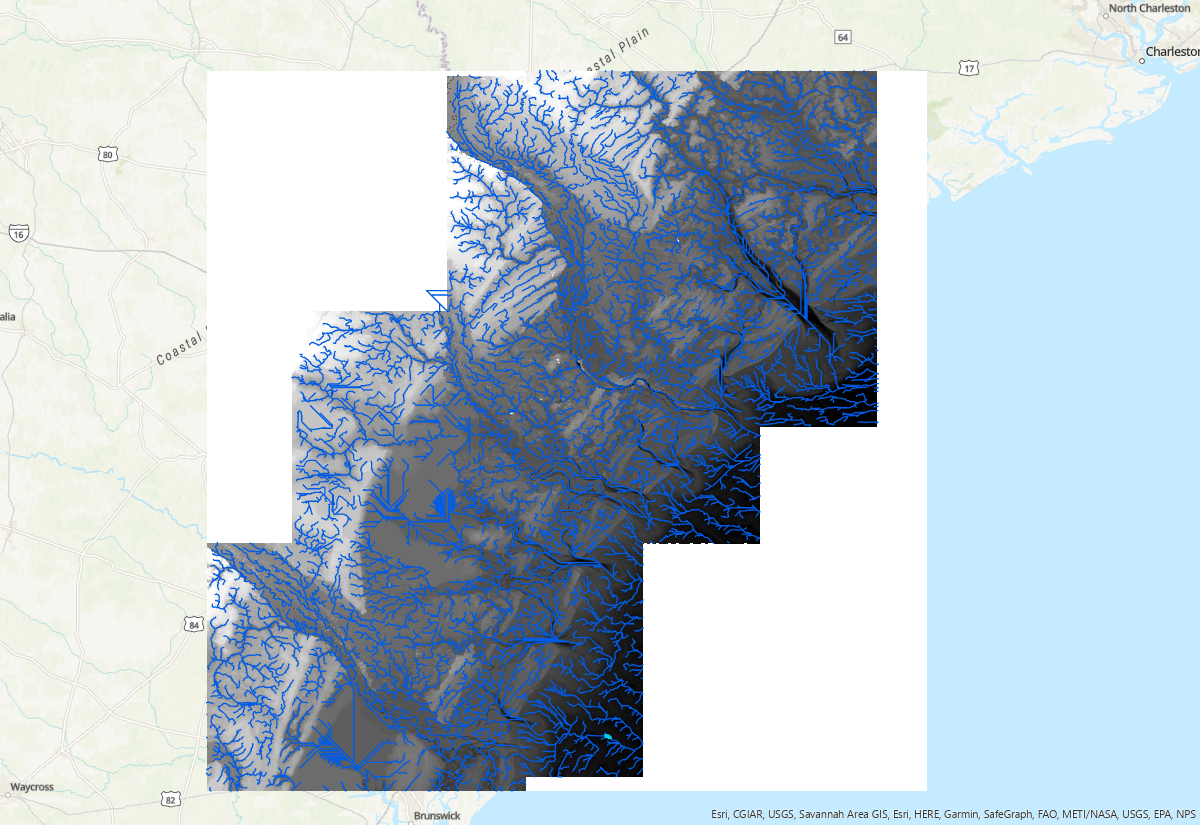
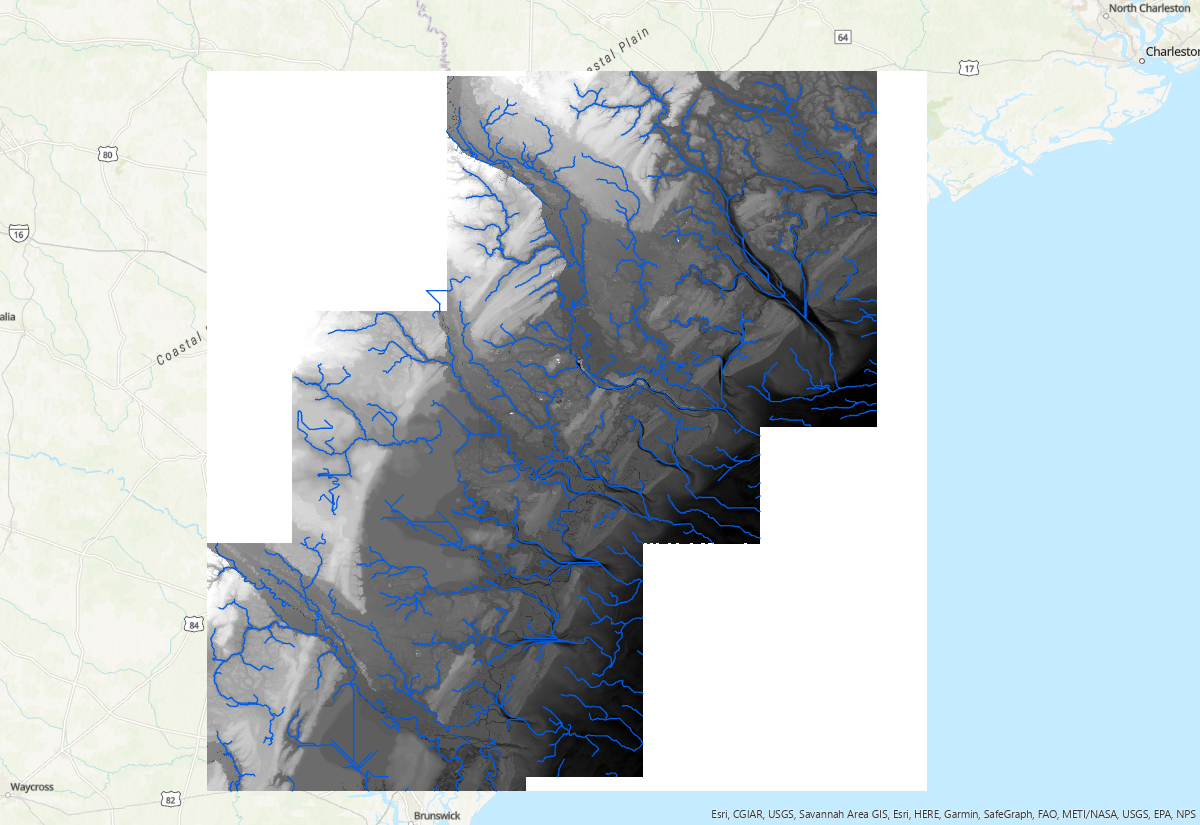
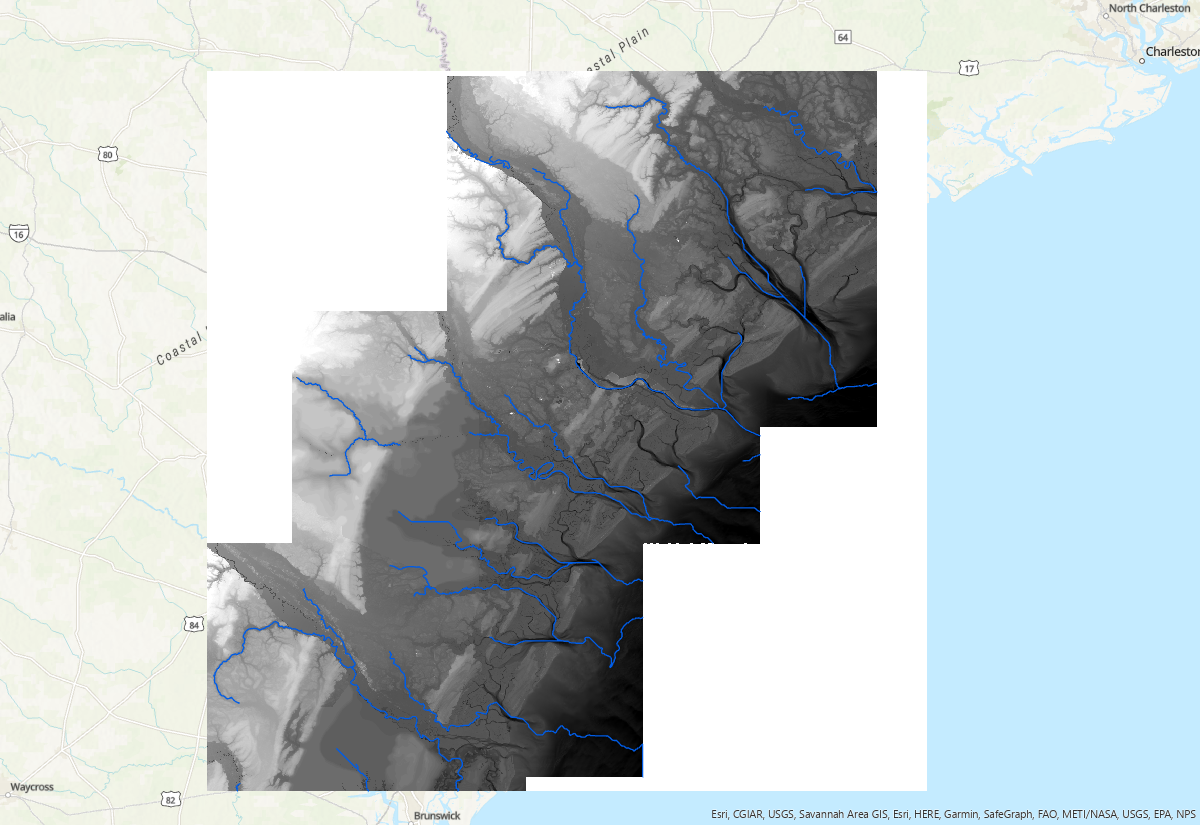
Scripts¶
Scripts are available from this Git Repo.
Dependencies¶
numpy
GDAL
geopandas
shapely
richdem
Workflow¶
-
Pre-processing DEM (optional)
1.1 Split large files
Sometimes, it is necessary to split large tif files into smaller ones to avoid memory issues. Script split2tiles.py serves for this purpose:
Run the script with this command: Create tileindex shapefile, which will be used in the next step: 1.2 Merge tilesimport os, sys from osgeo import gdal dset = gdal.Open(sys.argv[1]) width = dset.RasterXSize height = dset.RasterYSize tilesize = 8100 for i in range(0, width, tilesize): for j in range(0, height, tilesize): w = min(i+tilesize, width) - i h = min(j+tilesize, height) - j gdaltranString = "gdal_translate -ot Float32 -of GTIFF -srcwin "+str(i)+", "+str(j)+", "+str(w)+", " \ +str(h)+" " + sys.argv[1] + " " + sys.argv[2] + "_"+str(i)+"_"+str(j)+".tif" os.system(gdaltranString)
This process is needed when Each tile and its 8-connected rasters are mereged into one raster file, which will be used in the next step.import subprocess import multiprocessing as mp import numpy as np import geopandas as gpd from osgeo import gdal def merge_tiles(itile, df, maps, locations): dx = [-8100, 0, 8100, -8100, 0, 8100, -8100, 0, 8100] dy = [-8100, -8100, -8100, 0, 0, 0, 8100, 8100, 8100] ullon, ullat = int(df.location.split('_')[2]), int(df.location.split('_')[3].split('.')[0]) tiles = [] for j in np.arange(9): try: ilon = ullon + dx[j] ilat = ullat + dy[j] key2 = f'{ilon}_{ilat}' tile_idx = tilemaps[key2] tiles.append(locations[tile_idx]) except: print(f'No tile') cmd = f'gdal_merge.py -n -9999 -o Merged/JAPAN_merged_{str(itile).zfill(3)}.tif' subprocess.call(cmd.split()+tiles) if __name__ == '__main__': gdf = gpd.read_file('tileindex_japan_dem.shp') tilemaps = dict() for i, p in enumerate(gdf['location']): x = gdf.iloc[i].location.split('_')[2] y = gdf.iloc[i].location.split('_')[3].split('.')[0] key = f'{x}_{y}' tilemaps[key] = i npool = 15 pool = mp.Pool(npool) pool.starmap(merge_tiles, [(i, gdf.iloc[i], tilemaps, gdf['location']) for i in np.arange(len(gdf))]) pool.close() del pool -
Extract channel network
Fill depression:
Algorithm "Priority-Flood+Epsilon" (Barnes et al., 2014) is used here to fill depressions in the DEM. This algorithm increases every cell in a depression to the level of that depression's output, plus an additional increment which can direct flow to the periphery of the DEM.Flow direction:
Compute watershed (Flow accumulation and channel links):
Extract rivers:
References
C. Barnes, R., Lehman, C., Mulla (2014). Priority-flood: An optimal depression-filling and watershed-labeling algorithm for digital elevation models. Computers & Geosciences 62, 117–127. doi:10.1016/j.cageo.2013.04.024.
Barnes, Richard. 2016. RichDEM: Terrain Analysis Software. http://github.com/r-barnes/richdem.